A lack of product managers in the security function is burning out security leaders and making their direct reports miserable.
Career transition
In January of 2020, I took a new role at my B2B SaaS employer as the “Lead Security and IAM Product Manager”, after doing security engineering and architecture work at the same company for the prior 7 years. I learned a lot, and I was especially lucky to report to someone with deep product experience and a keen interest in leveling up his direct reports (thank you, Chris!). I had gotten plenty of exposure to the company’s customer base as a security professional, but now as a product manager, I was spending 15-20 hours per week talking to customers and unblocking the sales/renewal cycle if some major challenge came up. I became well-known for making big problems go away, and it was very satisfying work.
Unfortunately, it was also freaking exhausting. Being ‘on’ for call after call, day after day, took everything out of me. Marty Cagan, a well-known thought leader in the tech sector product management space, has said many times that a good product leader probably works 60 hour weeks (remember that, we’ll be coming back to it). I absolutely found that to be true; you spend 40 hours in meetings, and then spend your evenings doing all the things you promised yourself you’d somehow get done during the day.
In spring of 2022, I logged on to LinkedIn and switched on the “open to work” feature and tossed out a few long shot resumes to big-name midsized tech companies. I also wished to transition back to security work full-time.
During the interview process, I was excited to talk with security leaders about how this product management experience had helped make me more valuable to security teams. After all, security teams focus on providing value to the business (and in some cases, directly to the customer as well).
I quickly found that the skills I had developed as a product manager were not particularly highly valued in the security world. None of the security teams I interviewed for had dedicated product managers or program managers, yet few of the leaders I spoke with had any interest in discussing this part of my background. Invariably, the discussion with the security director would end up going something like this:
Me: “… and that’s why I think it’s important to ensure you aren’t building something you believe you need, but to focus on building things you know you need from the metrics you’ve collected and the business objectives you’ll enable.
Director: “Yeah yeah that’s cool. Just to clarify though, can you code?
Me: “Yes.”
Director: “Great. I believe we need to build an in-house replacement for Snyk.”
spoiler: they didn’t
I would be prized for my technical chops and soft skills, but nothing more. That’s a shame because:
Security programs are a product team; treat them like one!
Remember 10-15 years ago when tech company “sysadmin” teams ran out of the IT side of the business? Product would write some code, give some grumpy sysadmin the binary, and grumpy sysadmin would put it on the server at 10pm on a Friday?
btw I’m allowed to say all of that, I was a young, sorta-grizzed sysadmin from 2007-2011
Turns out that wasn’t a great way to build software, so along came DevOps, then Infrastructure/SRE roles, shift left, yada yada. Before long, these infra-focused teams had scrum masters, product managers, program managers – all the trimmings of your “standard” engineering organization.
Security is now an engineering function!
(…except we forgot to tell them)
Strangely, security only sort of got that same treatment. Security functions likewise arose out of IT and were transferred into the engineering organization, but (from talking to my peers), it seems that getting a fully-stacked deck of supporting functions is somewhat rare.
This causes what I’ll call “Manager-Injurious Security Engineering Repetition And Bastardized Leadership Expectations”, or MISERABLE for short.
Manager-Injurious Security Engineering Repetition And Bastardized Leadership Expectations
In MISERABLE, there are no product managers. Customer and business requirements go straight to the manager or director of security. This leader then attends endless meetings to identify the:
- Security program needs from customer, cross-functional, and compliance lenses
- Business objectives to be fulfilled
- Vision for the team’s offerings
- Roadmap to delivering those offerings and their value
- Metrics to collect and measure for the effectiveness of the services being provided
You know… product management. Unfortunately, security leadership is taking on this burden, along with a few other minor things like:
- Being included on every single security incident, no matter how minor
- Attending all team/subteam meetings and standups
- Attending cross-team meetings and standups
- Attending leadership team meetings
- Budgeting / expense approvals / “et cetera business stuff”
- Hiring
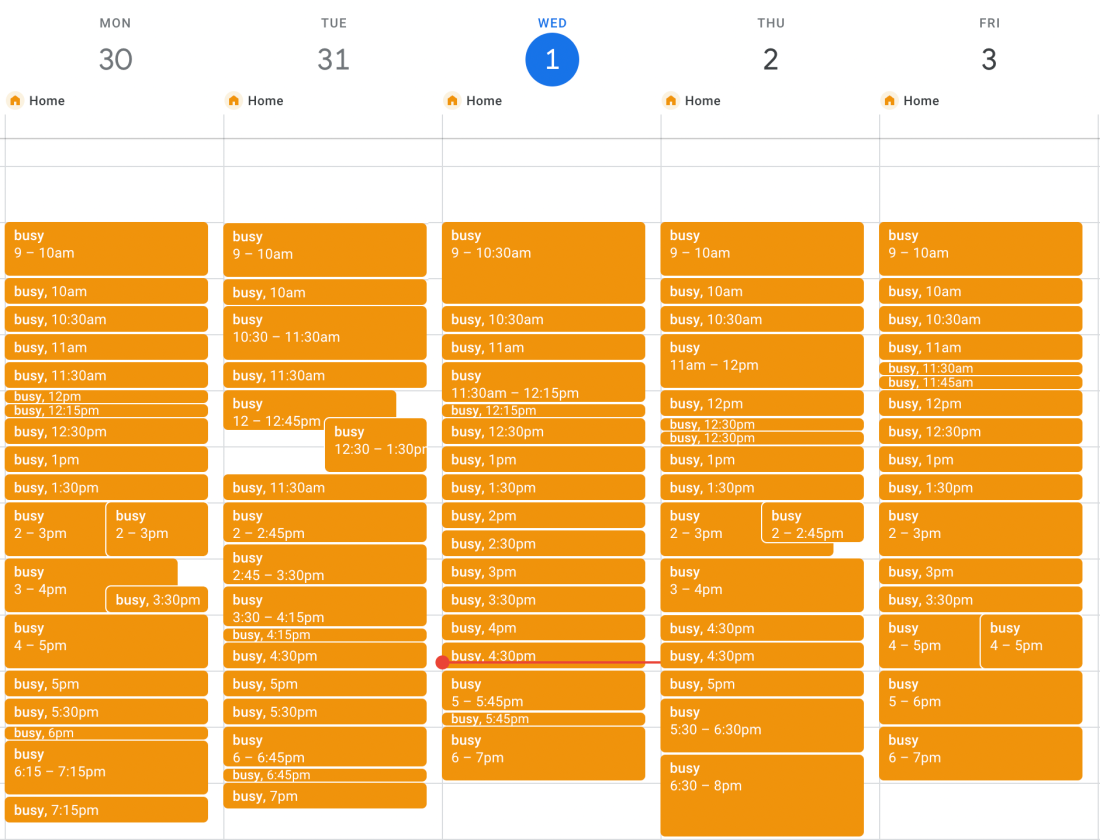
Now that person has a calendar that looks like this:
You know what wasn’t on those lists? Building and maintaining a happy, healthy team of people.
While I’ve attempted to make MISERABLE a humorous acronym, this really is an injurious loop that traps good engineers and their leadership in a death spiral. Security leaders are destined to not properly support their direct reports and individual contributors. Left with all the responsibilities above, they instead feel constantly overwhelmed. Without being given a defined line where they can stop giving a shit, the security leader must juggle being both a leader and a product manager – an almost laughable amount of cognitive load for any single person to take on. You may recall from the top of the post that many product managers consider 60 hour work weeks to be perfectly normal. If we can all agree that being a good team leader is at least a 40 hour per week job… well, do the math.
High-performing engineers get tired of the chaos, the lack of mentoring, and being seen as either a firefighter or future scapegoat. Faced with unclear career prospects and the maintenance of a mountain of tech debt from half-baked solutions, these engineers will inevitably leave for greener pastures. Many will come to find that their new teams suffer these same problems, and leaders will search endlessly for the cure for the symptoms (“we need more headcount!”), but not the disease.
“Just throw more engineers at it.”
I tend to believe that engineers are simply really smart people who want to be let loose at interesting problems. For example, a friend and colleague of mine went all-in on converting our company’s containers from a hodgepodge of base operating systems to a standardized, well-configured single image. Now, we had a specific reason we were trying to do this (the company wanted to sell software to a specific customer with strong opinions), but that’s not what motivated my friend. Some potential customer’s request was simply my friend’s MacGuffin for tackling a problem that had bothered him for years. My friend was motivated to spend night after night for weeks toiling away at it because it was 1) annoying and 2) freaking hard. That’s it. That’s why the itch was scratched.
Now the problem is that the security field has a tendency to focus on solving problems exclusively with technological solutions. An engineer hears, “we need a specific OS”, and away they go on standardizing. A security product manager hears, “we need a specific OS”, and the first thing they’ll say to you is, “Are we super duper sure that the customer is going to require this? Are they willing to pay more for us to do this work for them (btw has anyone talked to product marketing yet)? Are there specific services or sets of services they will require this for vs doing a blanket migration on everything? Can we get creative with scope to reduce our potential workload? Can we write policy language which carves out certain systems that may be very difficult to migrate?”
You’ll stare back at your security product manager and say, “yeah, I don’t know 🤷”, and they’ll immediately go off on a weeks-long journey to find out. It’s their job.
You may be thinking, “my security leaders do all that stuff.” First: I definitely don’t believe you. Second: even if they do a lot of that work, are they miserable? Are they working all day and night? Are they actually focused on their primary job duty of leveling up the skills and careers of everyone around them? Are they laser-focused on being strategic, not reactive?
Interestingly, it is also hard for security leaders who operate without a product manager function to delegate effectively. A staff level engineer may be an incredible architect and communicator, but they will find performing discovery, roadmapping, consensus building, and design to be particularly interesting? Can they sit at the perfect intersection of user experience, tech, and business considerations? Will they be absolutely miserable sitting in meeting after meeting re-hashing the same discussions over and over with 8 different stakeholder teams?
No, instead of delegating, the security leader will handle it themselves, brushing off offers of assistance with sincere gratitude. The security leader knows that it’s best to keep the talented engineer focused on engineering problems, lest we add to their already significant cognitive workload.
“I can provide air cover, don’t worry about that stuff.”
So, now what?
I’m not saying I have all the answers, but it’s clear that whatever we’re doing isn’t working. Mental health (a topic very near and dear to me personally) in this field has reached an abysmal state. Security practitioners are burned out. Multiple colleagues have told me they’ve experienced depression or severe anxiety. We’re all just sitting with bated breath, waiting to find out which company is going to get popped this week.
I believe the most important thing we can do is to free up our leaders to lead; to grow teams and guide careers. Then, we need to support our teams by providing them with the tools they need to be successful. If we’re going to shove all tech-related functions under the “product engineering” umbrella, we must be willing to support them like actual product teams as well.
So if you have the power to do so, consider hiring a security-focused product manager. Strong candidates should have prior experience as security practitioners, and they’ll cost the same as an experienced engineer. This is expected; this is good. Empower them to build the roadmap, be the face of security cross-functionally, and to seek out and drive conversations with the customer. Let them be the interface between you and the product management leadership chain; a good security product manager can be the deciding factor for if the head of product sees your team as an enabler or as a hindrance.
Good luck, I’ll be rooting for you.