
IT and security professionals: you are free to copy and modify this content however you’d like without attribution. I encourage the reuse of this content for your own internal documentation or guides.
In this post, I’ll start by providing instructions for using Touch ID, Face ID, or your phone PIN code as the MFA for your Okta account, and then wrap up with a brief explanation of why this form of MFA is unbreakable.
Step-by-step
For starters, this only works on Safari or Chrome/Chromium-based browsers (such as Brave). Sorry Firefox users, there’s no support quite yet, but it’s hopefully Mozilla will add it soon. Second, you must already have Touch ID, Face ID, or a lock screen PIN configured on your device. Here’s Apple’s guide for setting up Touch ID on your MacBook.
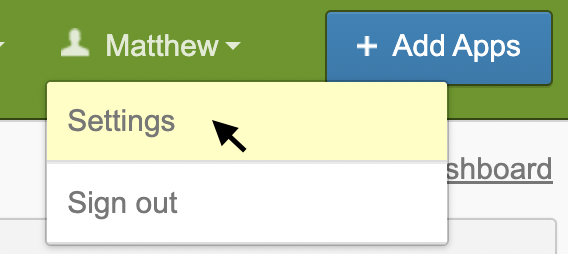
- Using the device you plan to authorize as one of your trusted devices (e.g. your phone or laptop), sign in to Okta and select your name in the top-right corner. Choose ‘Settings’.
- Click the ‘Edit Profile’ button on the top-right corner. You will likely be challenged to enter credentials again.
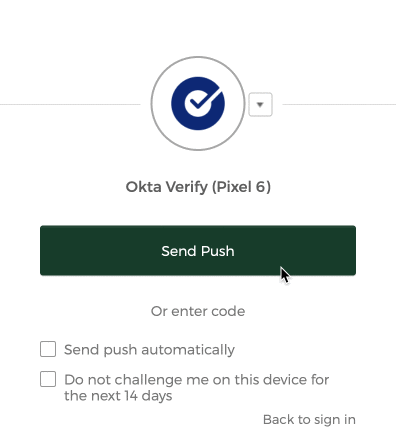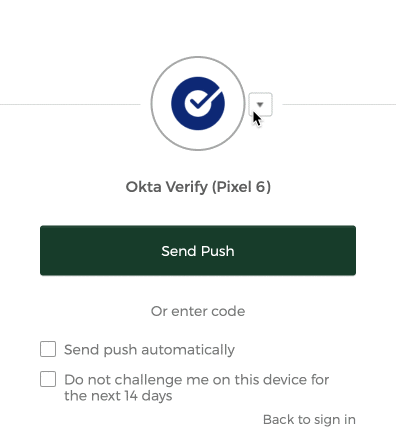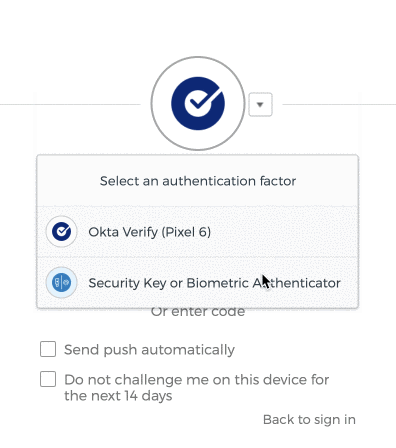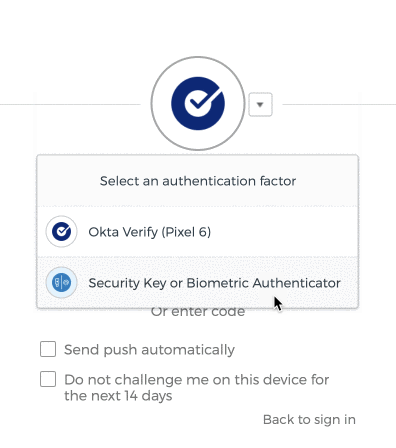
- Scroll down until you find ‘Extra Verification’ section on the right side of the page. Select the ‘Set up’ or ‘Set up another’ option under ‘Security Key or Biometric Authenticator’.
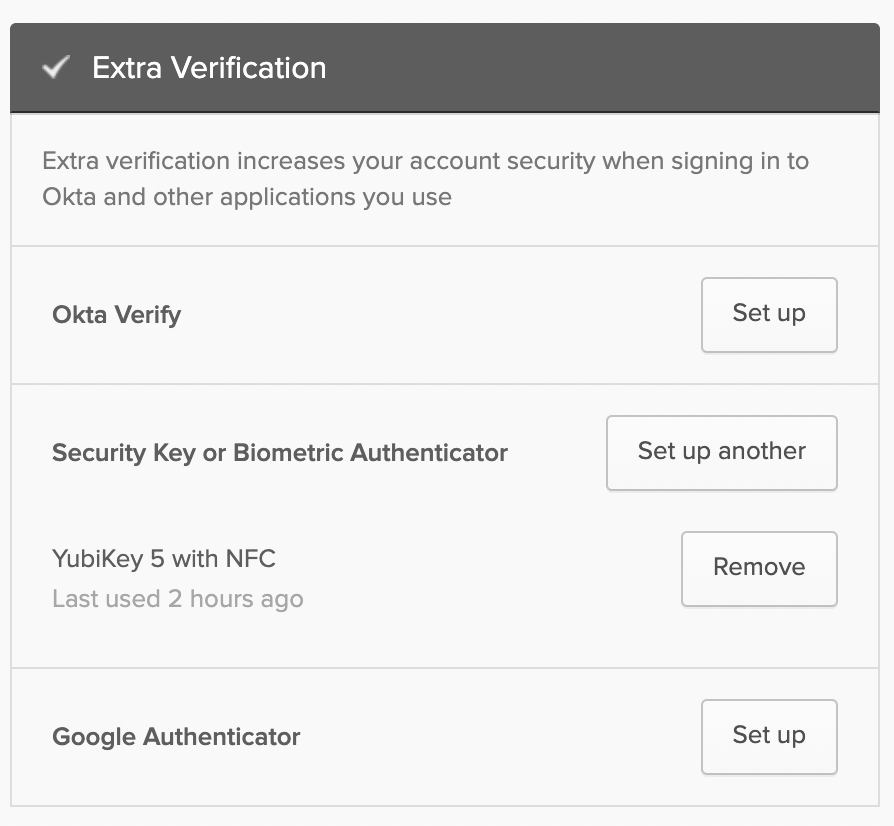
- You will be taken to the MFA enrollment page, and it may look different to you depending on if you already have strong MFA devices configured. Select ‘Set up’ or ‘Set up another’.

- On the next page, click the ‘Enroll’ button.
💻 For setting up a new factor with your MacBook:
Chrome will prompt you asking which device you’ll be utilizing for MFA. Select ‘This device’. You will then be prompted to press your finger to your Touch ID reader.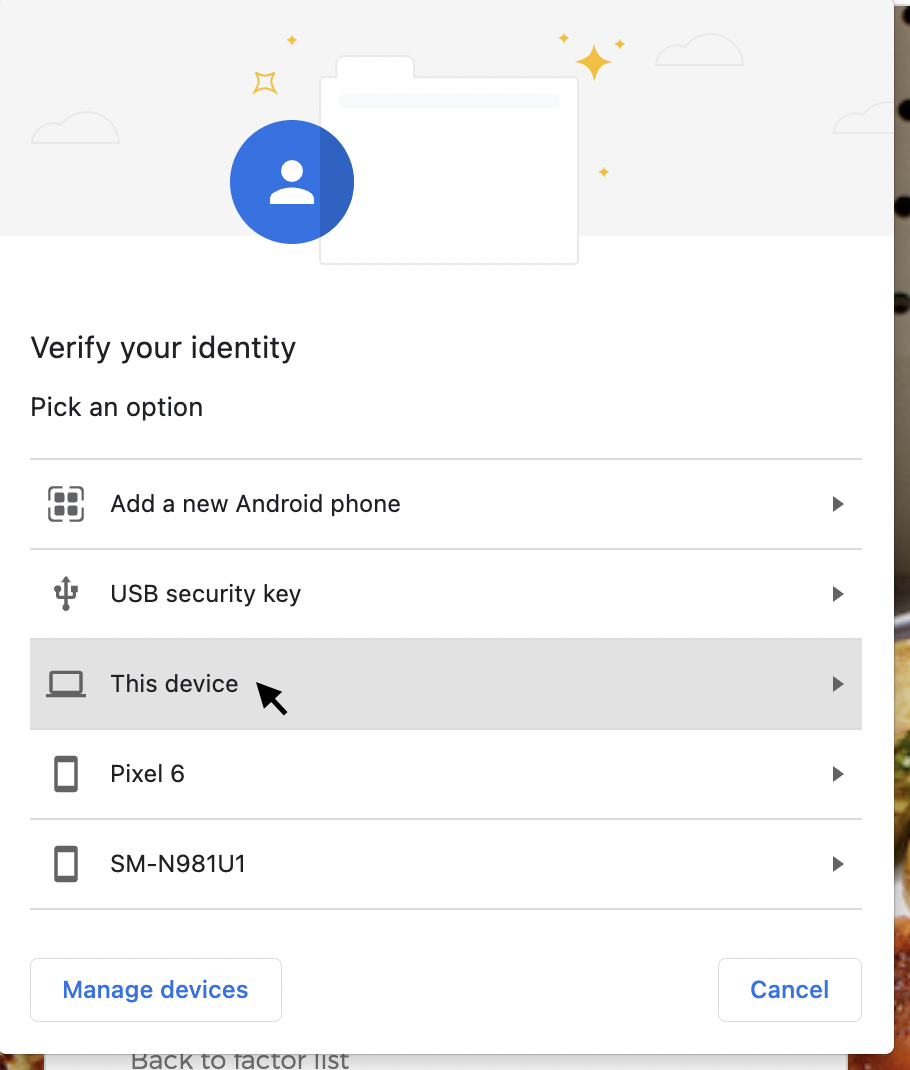
For setting up a new factor with your iPhone or iPad
Your iOS device will ask you to verify your Face ID or Touch ID, just as you would to unlock your phone.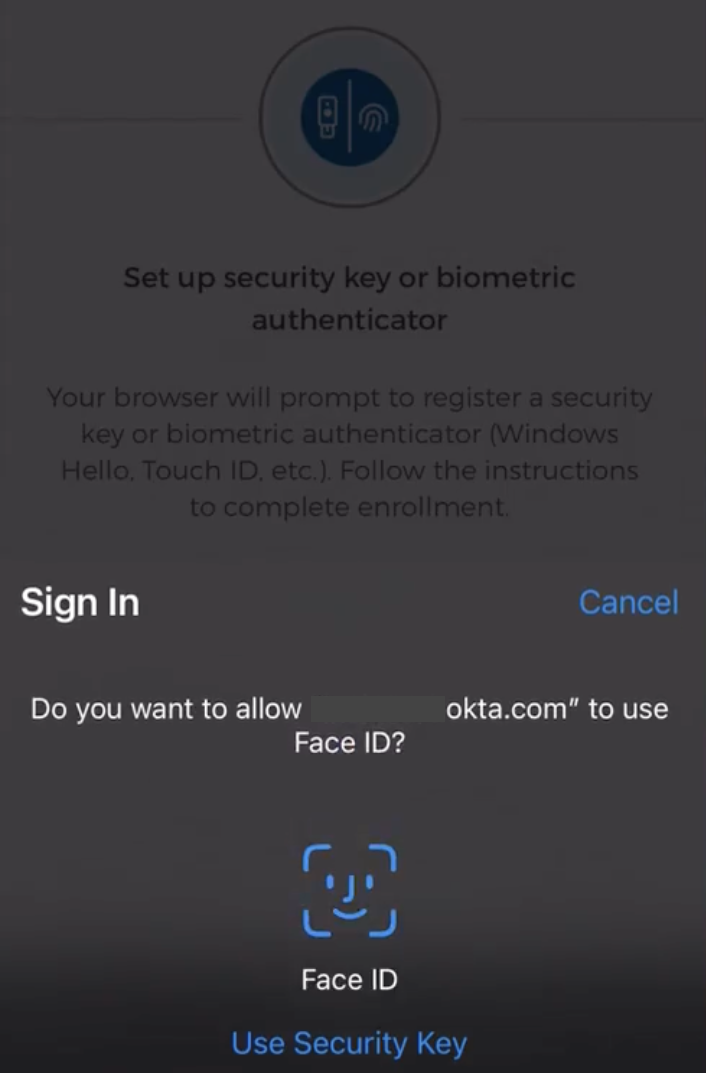
🤖 For setting up a new factor with your Android
Select ‘Use this device with screen lock’ to utilize your phone’s unlock screen as your MFA method. Depending on your phone’s configuration, unlocking with fingerprint or face matching may also be available options, and these are acceptable as well.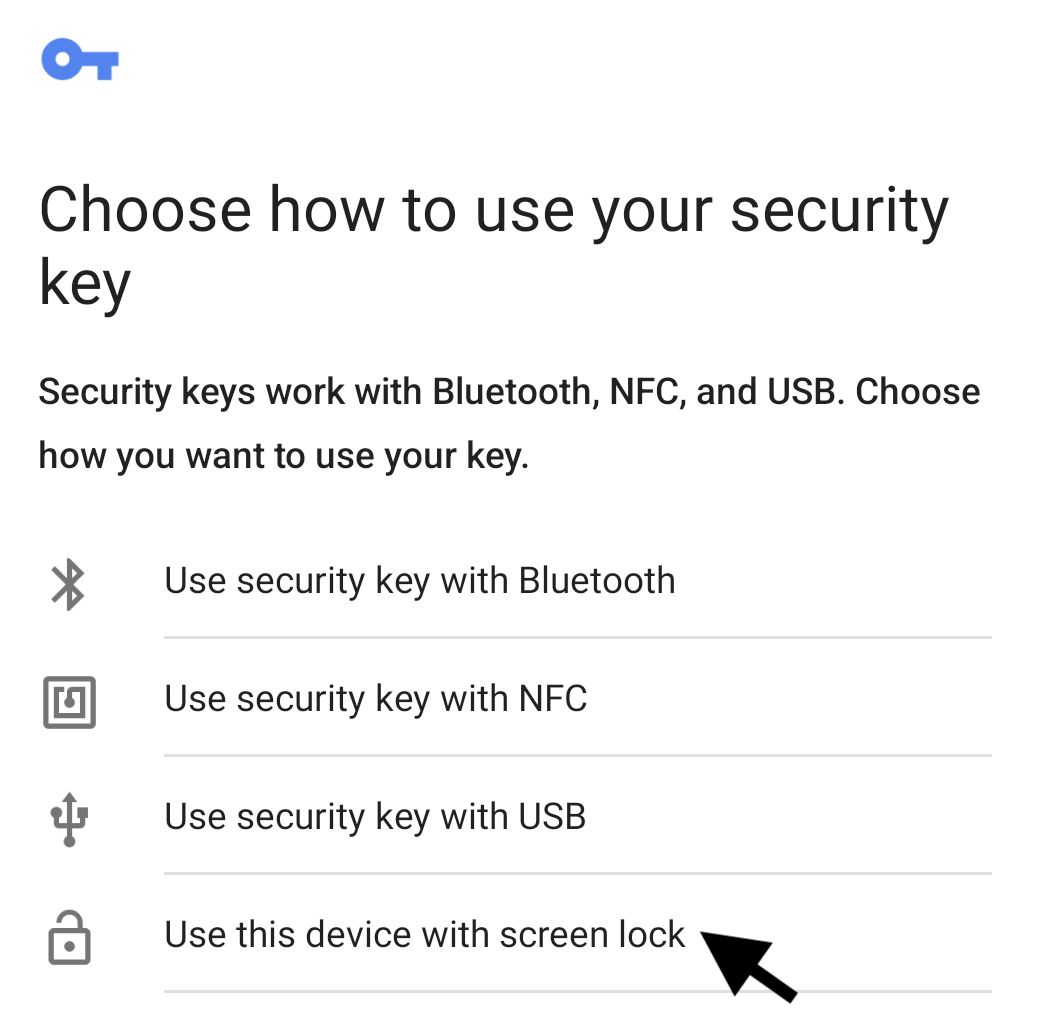
- After enrolling your device, you will be returned to your Okta settings page. You should receive a success confirmation.
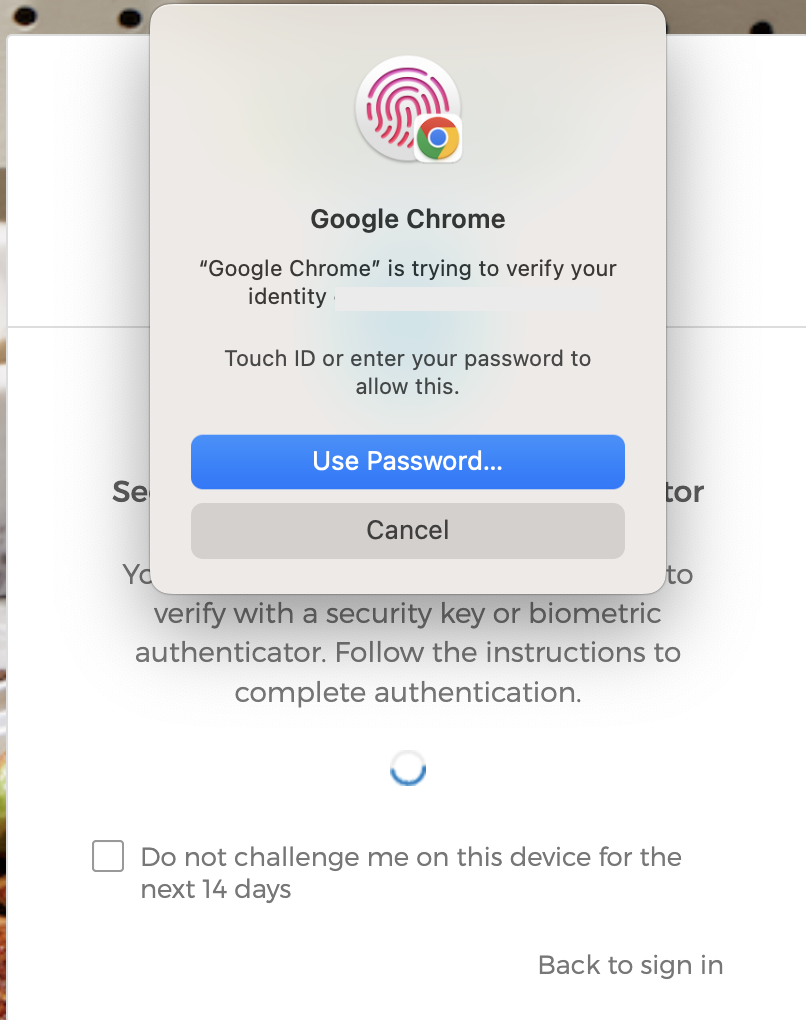
- For all subsequent logins, Okta should automatically prompt you to verify with Touch ID, Face ID, or your phone’s PIN.
- If Okta prompts you for some other MFA method, you may need to manually select the proper option, ‘Security Key or Biometric Authenticator’.
That’s it, you’re all set! Log out of Okta and attempt to log back in, just to ensure everything is set up and working well.
Now, I would also recommend you go and purchase an unphishable authenticator for personal use, and then utilize that as your backup option for your work account. This will also allow you to get logged in from a new mobile device without having to contact your IT department to get your MFA reset.
My personal recommendation is the YubiKey 5C NFC (Amazon, $55 USD)†, which can not only plug in to your Mac if Touch ID fails you, but can also be used from your phone thanks to NFC (NFC is the technology that allows you to tap to pay). I will disclaim that the NFC part can be fickle, so you’ll need to practice and find the right spot on your phone where the scan will work consistently.
It’s worth repeating: you should be using an unphishable MFA device for your high-impact personal accounts. So consider the purchase of a USB device as nice two-for-one; you get to protect your personal accounts, and you get to ensure you don’t get stuck locked out of your work account if you need to get on from a new device.
Set up your backup by going back to this step and selecting ‘USB security key’, then inserting your YubiKey or similar device. Once you have Touch ID, Face ID, or phone PIN and a USB backup configured, don’t forget to go back into your Settings and remove any unsafe MFA methods you previously had configured (such as SMS, Okta Verify, or Google Authenticator).
† And no, I am not getting a commission or paid in any way if you buy one of those from the link above. I just care about you and your safety 🙂
Why is this important?

The Problem
This was a tough summer for security professionals. The writing has been on the wall for some time, but it’s now clear from large-scale and high-impact compromises of major tech companies that most forms of multifactor authentication (MFA) are not going to be sufficient to stop today’s unskilled attackers, let alone the highly talented ones. Tech news outlets have even covered how entire toolkits are available in criminal marketplaces for just a few hundred U.S. dollars.
In short, attackers are now either:
- Collecting MFA codes and simply forwarding them to the service they wish to break into while the code is still valid.
- Sending push notifications to apps like Okta Verify or OneLogin Protect over and over, until the target simply gives in and hits approve.
The Solution
These new, OS-native MFA solutions like Touch ID, Face ID, or phone PIN are all utilizing a new standard for authentication called Webauthn. There’s plenty of information already written on the standard, but in short: Webauthn ties an authenticator (like Touch ID) to a specific website, and does so in a way that is invisible to the user. There’s no ability to trick a user into, for example, reading an MFA code over the phone to an attacker. If a victim is phished and isn’t actually at the real Okta, their browser will not provide the right information to complete the Webauthn challenge. Webauthn is phish-proof!

