Recently, I needed to access an internal Application Load Balancer (ALB) on a private network segment within one AWS account (the “server” account) from another AWS account (the “client” account). API Gateway seemed like a logical choice for solving this problem, but actually successfully building the solution was terribly painful. Now that I’ve figured it out myself, hopefully I can save you some time! This blog post will walk you through the components involved and how they work together to offer a secure and elegant solution.
Before we go any further though, I want to put a big warning right up front: at the time of writing, API Gateways have a maximum timeout of 30 seconds and this cannot be raised. So please remember this as you are thinking about your use-case and whether or not this solution will work for you.
Alright, with that out of the way, let’s talk nerdy.
A Few Definitions
- API Gateway:
- The API Gateway serves as the entry point for clients making HTTP requests that need to be routed to the internal ALB. It lives in the “server” account with the ALB.
- VPC Link:
- The VPC Link in API Gateway allows you to connect your API routes to private resources within your VPC. In this scenario, it provides the bridge between the API Gateway and the internal ALB.
- Integration:
- This component defines how API Gateway should route traffic to the ALB. In our case, we will be proxying all traffic to the ALB over HTTPS (TLS).
- Route:
- This resource defines how incoming requests should be routed. Our route uses AWS IAM for authorization, ensuring that only security principals from our trusted AWS account can access the API Gateway.
- Stage:
- Stages in API Gateway represent different versions of your API. Here, we set up a default stage that automatically deploys any changes.
Securing the API Gateway with AWS IAM
API Gateway offers a few options for authorizing access, one of which is AWS IAM. By leveraging IAM roles and policies, you can control who can invoke your API and what actions they can perform. This means we can add security to our API Gateway without needing to deal with secrets, keys, or outside identity providers. Simplicity for the win!
We will be creating a role in the same AWS account as the API Gateway (which again, we’re calling the “server” account), and we will give that role access to invoke the gateway. Finally, we will allow the role to be Assumed cross-account from our “client” account.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::123456789123:role/api-client-production"
]
},
"Action": "sts:AssumeRole"
}
]
}
# Policy to attach to the above invocation role
{
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = "execute-api:Invoke"
Resource = "${aws_apigatewayv2_api.apigw_http_endpoint.execution_arn}/*/*"
}
]
}
It’s worth noting that this configuration only allows one security principal in my “client” AWS account to access the gateway. This least-privilege mechanism is definitely the safest way to design this solution. However, there may be times where you want any security principal in the “client” AWS account to reach the internal ALB through the API Gateway. To do that, we can modify the role like this instead:
{
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Principal = {
AWS = [
"arn:aws:iam::123456789123:root"
]
}
Action = "sts:AssumeRole"
}
]
}
How API Gateway Proxies Requests to ALB Using VPC Link
Out of the box, AWS API Gateway has no way to reach into our VPC in order to access our ALB. However, AWS does offer a great solution for this called VPC Link, which creates an ENI within the VPC on a set of configurable subnets. Once VPC Link is configured, we can securely route requests to resources within a private VPC.
“Show Me the Terraform!”
Below is the complete Terraform required for setting up this architecture.
# Create the VPC Link configured with the private subnets.
resource "aws_apigatewayv2_vpc_link" "vpclink_apigw_to_alb" {
name = "apigw-to-alb-vpclink"
# The VPC Link security group does not need ingress rules but must allow egress of HTTPS traffic.
security_group_ids = ["sg-12345678"]
# Match the private subnets that the ALB listener is attached to.
subnet_ids = [
"subnet-0784edad240a704272",
"subnet-01db9bf70386021c",
"subnet-e5d54452fde73fcb2"
]
}
# Define the API Gateway resource
resource "aws_apigatewayv2_api" "apigw_http_endpoint" {
name = "apigw-to-alb-gateway"
protocol_type = "HTTP"
description = "API Gateway that accepts traffic from the Security AWS accounts and forwards it to the AI Gateway ALB."
}
# Define our gateway's integration (that is, what should it send traffic to?)
resource "aws_apigatewayv2_integration" "apigw_integration" {
api_id = aws_apigatewayv2_api.apigw_http_endpoint.id
integration_type = "HTTP_PROXY"
# Set this to the ARN of the target ALB's *listener* (which is different than just the ALB ARN)
integration_uri = "arn:aws:elasticloadbalancing:us-east-1:123456789123:listener/app/my-alb-name-b6aa97/0d73e057bcffa2d5/fb08b9ab67bdb727"
tls_config {
# By setting this value, the API Gateway will validate TLS certificates.
# This needs to be the domain name of the internal ALB
server_name_to_verify = "internalalb.domain.name.here.mycompany.internal"
}
integration_method = "ANY"
connection_type = "VPC_LINK"
connection_id = aws_apigatewayv2_vpc_link.vpclink_apigw_to_alb.id
payload_format_version = "1.0"
depends_on = [aws_apigatewayv2_vpc_link.vpclink_apigw_to_alb,
aws_apigatewayv2_api.apigw_http_endpoint]
}
# API GW route with ANY method for all paths
resource "aws_apigatewayv2_route" "apigw_route" {
api_id = aws_apigatewayv2_api.apigw_http_endpoint.id
authorization_type = "AWS_IAM"
route_key = "ANY /{proxy+}"
target = "integrations/${aws_apigatewayv2_integration.apigw_integration.id}"
depends_on = [aws_apigatewayv2_integration.apigw_integration]
}
# Set a default stage
resource "aws_apigatewayv2_stage" "apigw_stage" {
api_id = aws_apigatewayv2_api.apigw_http_endpoint.id
name = "$default"
auto_deploy = true
depends_on = [aws_apigatewayv2_api.apigw_http_endpoint]
}
# Set who can invoke this API Gateway via AssumeRole
resource "aws_iam_role" "api_invocation_role" {
name = "apigw-to-alb-role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
"Principal": {
"AWS": [
"arn:aws:iam::123456789123:role/api-client-production"
]
},
Action = "sts:AssumeRole"
}
]
})
}
# Policy to attach to the above invocation role
resource "aws_iam_role_policy" "api_invocation_policy" {
name = "apigw-to-alb-policy"
role = aws_iam_role.api_invocation_role.id
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Effect = "Allow"
Action = "execute-api:Invoke"
Resource = "${aws_apigatewayv2_api.apigw_http_endpoint.execution_arn}/*/*"
}
]
})
}
# Generated API GW endpoint URL that can be used to access the AI Gateway application.
output "apigw_endpoint" {
value = aws_apigatewayv2_api.apigw_http_endpoint.api_endpoint
description = "API Gateway Endpoint"
}
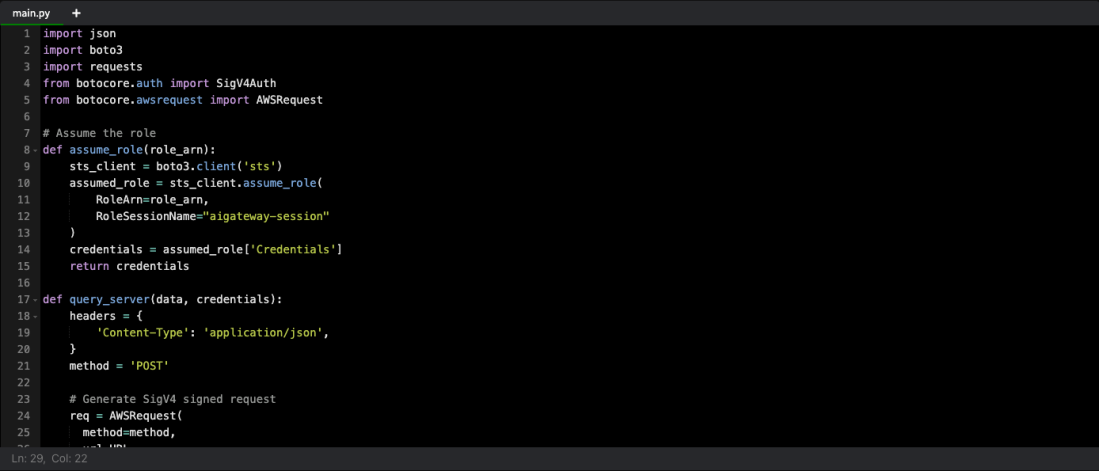
Wonderful, now we’ve got the AWS side configured! So let’s now prepare a Python Requests library HTTP request to call our ALB through this API Gateway mechanism. For this example, you can imagine we have stood up an EC2 server in the “client” AWS account and have given it a role, “api-client-production”, which you may recall from earlier is the role the “server” account is expecting to get an AssumeRole request from.
import json
import boto3
import requests
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
# Where to send some test data
URL = "https://driznofdpc.execute-api.us-east-1.amazonaws.com/submit/data"
# Role to assume that has been granted permission to call API Gateway
ROLE_ARN = "arn:aws:iam::987654321987:role/apigw-to-alb-role"
# Assume the role
def assume_role(role_arn):
sts_client = boto3.client('sts')
assumed_role = sts_client.assume_role(
RoleArn=role_arn,
RoleSessionName="apigateway-session"
)
credentials = assumed_role['Credentials']
return credentials
def query_server(data, credentials):
headers = {
'Content-Type': 'application/json',
}
method = 'POST'
# Generate SigV4 signed request
req = AWSRequest(
method=method,
url=URL,
data=json.dumps(data),
params=None,
headers=headers
)
SigV4Auth(credentials, "execute-api", "us-east-1").add_auth(req)
req = req.prepare()
# Send the request
response = requests.request(
method=req.method,
url=req.url,
headers=req.headers,
data=req.body
)
return response.json()
# Main function
def main():
# Assume the role and get temporary credentials
credentials = assume_role(ROLE_ARN)
# Update boto3 session with assumed role credentials
boto3_session = boto3.Session(
aws_access_key_id=credentials['AccessKeyId'],
aws_secret_access_key=credentials['SecretAccessKey'],
aws_session_token=credentials['SessionToken']
)
# Cache these somewhere, don't re-generate them on each request or you'll take
# a massive performance hit and also hit AWS STS API rate limits.
credentials = boto3_session.get_credentials().get_frozen_credentials()
response = query_server("Good morning!", credentials)
print(response)
if __name__ == "__main__":
main()
Time to run some Python! Let’s see what we get:
ubuntu@ip-10-11-46-143:~$ python3 hello_world.py
{"success": true, "message": "Hello from an internal ALB!"}
ubuntu@ip-10-11-46-143:~$
Ah, the sweet sweet smell of success!